一種機器學習方法,通過組合多個學習模型來獲得比單一模型更好的預測性能。就像集思廣益,多個模型的智慧結合,可以產生更準確、穩定的結果
Bagging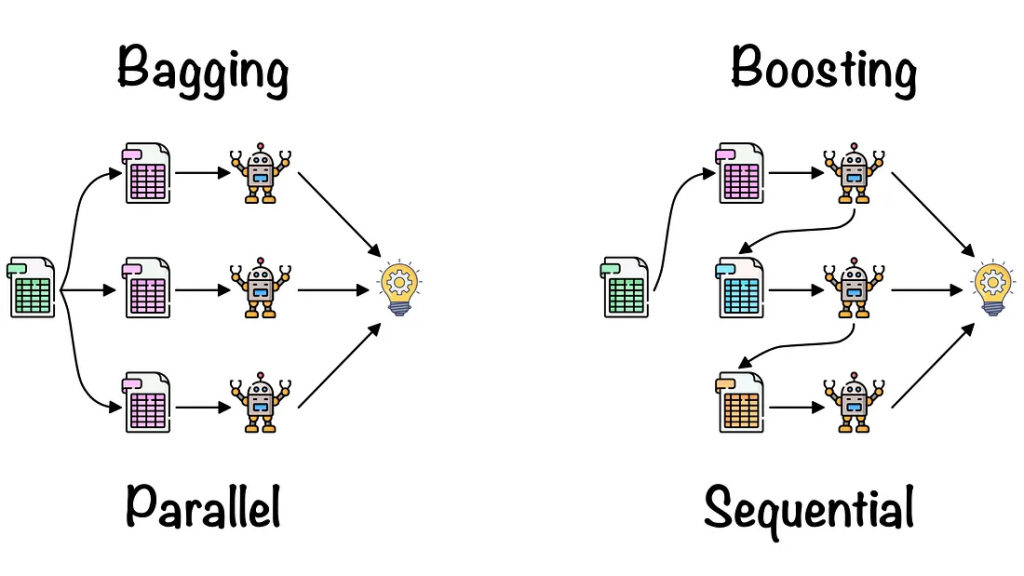
Boosting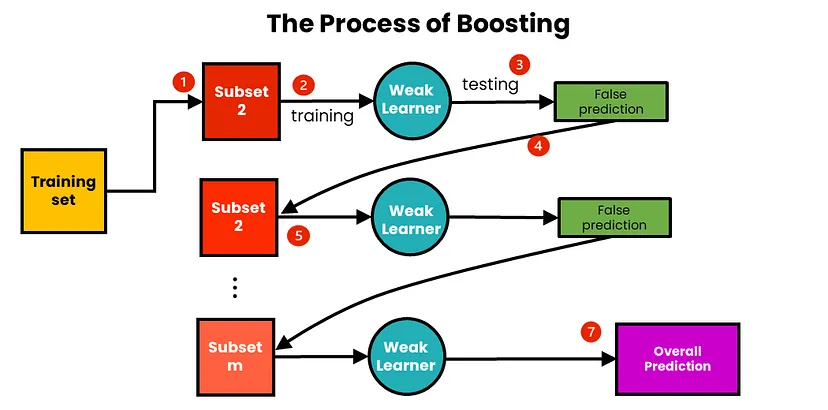
Stacking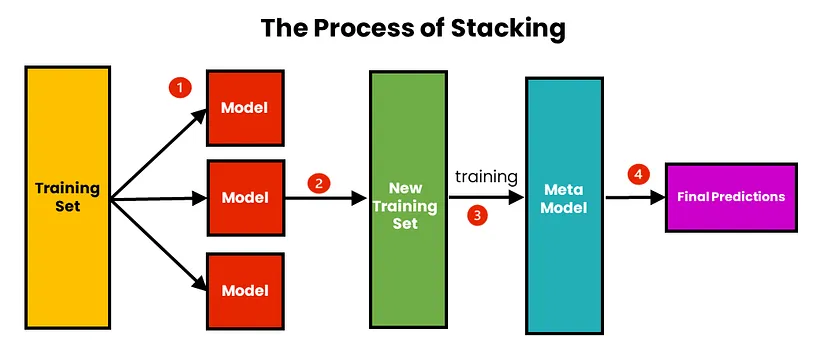
假設有T個基模型,每個模型的預測結果為h_t(x),則最終的預測結果H(x)可以表示為:
H(x) = argmax Σ_t=1^T w_t * h_t(x)
w_t是每個模型的權重
分類問題:垃圾郵件分類、情感分析迴歸問題:房價預測、銷售額預測推薦系統:提高推薦準確性異常檢測:發現異常數據from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
# 載入鳶尾花數據集
iris = load_iris()
X, y = iris.data, iris.target
# 分割訓練集和測試集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 創建隨機森林分類器
clf = RandomForestClassifier(n_estimators=100, random_state=42)
# 訓練模型
clf.fit(X_train, y_train)
# 進行預測
y_pred = clf.predict(X_test)
# 評估模型性能
from sklearn.metrics import accuracy_score
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)
集成學習是一種強大的機器學習技術,通過組合多個模型,可以顯著提高模型的性能。在實際應用中,選擇合適的集成學習方法,並對模型進行調參,是獲得最佳效果的關鍵


 iThome鐵人賽
iThome鐵人賽